|
NEURONALE NETZE 2
( Fortsetzung von Neuronale Netze 1 ) |
|
|
|
|
||
|
Data Mining |
||||
|
Information ist heute zu einem neuen (virtuellen) Rohstoff geworden, der ständig an Bedeutung gewinnt. Überall auf der Welt existieren riesige Datenbestände, die ab einem bestimmten Zeitpunkt weder weiterverwendet noch ausgewertet werden (wissenschaftliche Daten, Personalangaben bei Behörden, Daten in Gesundheitsregistern etc.). In solchen brachliegenden Datenhalden verbergen sich aber oft wertvolle Zusammenhänge, an die beim Anlegen der Datenbank noch niemand gedacht hat. Das Aufspüren von Regeln und Mustern in großen Datenbeständen, und deren Umwandlung in z. B. Prognosemodelle, ist das Ziel von Data Mining.
|
||||
|
||||
|
Für das Auffinden dieser verborgenen Zusammenhänge werden virtuelle (körperlose) Informationsroboter eingesetzt, die nach dem Prinzip künstlicher Neuronaler Netze arbeiten. Zahlreiche solcher Bots (vom Begriff robot abgeleitet) bevölkern heute schon das Internet als autonome Computerprogramme, und sie schürfen unermüdlich, Tag und Nacht, nach wertvollen Mustern.
Aufgaben wie Mustererkennung und das sich autonom Orientieren in oft fehlerhaften riesigen Datenbeständen stellen hohe Anforderungen, die von herkömmlichen Computerprogrammen nur unzureichend geleistet werden können. Menschliche Gehirne sind dafür wesentlich besser gerüstet, denn die Informationsverarbeitung mittels (biologischer) Neuronaler Netze ist robust gegenüber inkonsistenten Daten, fehlertolerant gegenüber internen Schäden (Nervenzellen im Gehirn sterben täglich ab, ohne die Arbeit des Gehirns zu beeinträchtigen), flexibel bei unterschiedlichen Anwendungen (indem es sich auf die neue Arbeitsumgebung durch Lernen einstellt), zudem zur Generalisierung fähig (durch geeignete Trainingsbeispiele werden Entscheidungsregeln ausgebildet, deren Gültigkeit über die Trainingsbeispiele hinausgehen) etc. Die Neuroinformatik versucht, mit Hilfe stark vereinfachter Modelle, die Arbeitsweise eines biologischen Neuronalen Netzes (Gehirn) nachzuahmen, sie zu verstehen und für technische Anwendungen nutzbar zu machen. Ein mathematisches Modell davon kann dann als Computersimulation das Internet bereisen und seine Arbeit aufnehmen. |
||||
|
Neuronale Netze |
||||
|
Das Grundkonzept eines Neuronalen Netzes ist relativ einfach. Ein Neuronales Netz besteht aus Neuronen und Nervenfasern (welche die Neuronen miteinander verbinden). Die Verbindungsstärke zwischen zwei Neuronen wird durch die Synapse bestimmt, und sie ist für das Funktionieren eines Neuronalen Netzes von ausschlaggebender Bedeutung. In einem künstlichen Neuronalen Netz wird das Neuron durch ein einfaches Rechenelement ersetzt, das nichts anders tut, als die von anderen (künstlichen) Neuronen einlaufenden elektrischen Signale zu gewichten und aufzusummieren. Überschreitet die Summe einen bestimmten Schwellenwert, feuert dieses Neuron nun selbst ein Signal ab, das wiederum von anderen Neuronen, mit denen es verbunden ist, gewichtet und aufsummiert wird usw.
Je nachdem wie diese (künstlichen) Neuronen miteinander verbunden sind, bilden sie bestimmte Netzwerkklassen mit ganz speziellen Eigenschaften und Anwendungsmöglichkeiten. Die große Herausforderung für den Bau eines künstlichen Neuronalen Netzes ist, die richtige Architektur und Verbindungsstärke (Gewichtung) zwischen den Neuronen zu finden. Die Natur hat dafür den Weg der Evolution gewählt: Generationen von Nachkommen, deren Nervensysteme gering variieren, und die Auslese jeweils jener Varianten, die am besten an die Umwelt angepasst sind. Dieser sehr zeit- und ressourcenaufwendige Prozess wird heute zum Teil in Computern simuliert. Auf diese Weise werden künstliche Neuronale Netze für die Lösung von sehr komplexen Aufgaben gewissermaßen gezüchtet. Damit zeichnet sich ein neuer Trend ab, Software in einer virtuellen Umwelt zu züchten, anstatt sie zu schreiben. Die Natur hat neben Mutation und Selektion auch den Vorgang des Lernens ausgebildet. Menschen und Tiere lernen aus Erfahrung, aber auch durch aktive Imitation. Erst 1995 wurden die so genannten Spiegelneuronen entdeckt, die im Gehirn während der Betrachtung eines Vorgangs die gleichen elektrischen Signale auslösen, als würde man die Handlung selbst begehen. Eine Erklärung dafür, warum Lachen ansteckend ist und wir den Schmerz anderer oft mitfühlen können. Eine andere wichtige Grundlage für das Lernen wurde 1949 von dem kanadischen Psychologen Donald Hebb (1904-1985) durch rein theoretische Überlegungen gefunden und erst mehrere Jahrzehnte später in Experimenten nachgewiesen. Sie ging als Hebbsche Lernregel in die Neuroinformatik ein und besagt, dass Verbindungen zwischen (wiederholt) gleichzeitig aktiven Neuronen verstärkt werden. Heute ist eine ganze Reihe solcher Lernregeln bekannt, nach denen künstliche Neuronale Netze trainiert werden. Sie werden in zwei Gruppen eingeteilt: a.) Unüberwachtes Lernen Lernen erfolgt hier durch Selbstorganisation. Ähnliche Eingabemuster werden assoziativ als ähnlich klassifiziert (z.B. bei Kohonen-Netzen). In diese Gruppe gehört auch die Hebbsche Lernregel. b.) Überwachtes Lernen (supervised learning) Es gibt eine Trainingsmenge von Eingabe- und Ausgabemustern. Zu jedem Eingabemuster existiert ein eindeutig korrektes Ausgabemuster. Die synaptischen Verbindungsstärken (Gewichtungen) werden solange verändert, bis die Paarung (Eingabemuster - Ausgabemuster) für die Trainingsmenge stimmt. Das entspricht dem Lernen aus Fehlern. Beispiele dafür sind die Delta-Lernregel für zweischichtige Netzwerke und die Backpropagation-Lernregel für mehrschichtige Netzwerke. |
||||
|
Rotkäppchen und „Die Matrix im Kopf“ |
||||
|
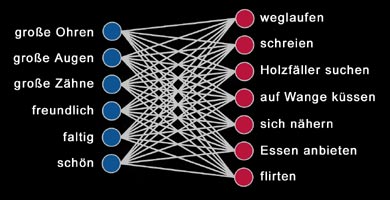
Der Klassiker unter den künstlichen Neuronalen Netzen ist das Perceptron (nach engl. perception, Wahrnehmung). Das sind mehrschichtige Netze mit festen Eingabe- und Ausgabeschichten von Neuronen, ohne Rückkopplung. Die zwischen der Eingabe- und Ausgabeschicht liegenden Schichten werden als Hidden Layers (versteckte Schichten, Zwischenschichten) bezeichnet. 1987 haben Jones & Hoskins demonstriert, wie sich bereits mit solch einem zweischichtigen Netzwerk (also noch ohne Hidden Layer) das Verhalten von Rotkäppchen modellieren lässt.
|
||||
|
||||
|
Die Trainingsmenge wird im folgenden Text festgelegt (in den USA wird das Märchen von Rotkäppchen - Little Red Ridinghood - etwas anders erzählt):
„Rotkäppchen muß lernen, wegzulaufen, zu schreien und den Holzfäller aufzusuchen, wenn sie einem Wesen mit großen Ohren, großen Augen und großen Zähnen (dem Wolf) begegnet. Sie muß lernen, sich Wesen anzunähern, die freundlich und faltig sind und große Augen haben (die Großmutter), sie muß sie auf die Wange küssen und ihnen essen anbieten. Weiterhin muß sie lernen, sich Wesen, die schön und freundlich sind und große Ohren haben (der Holzfäller), anzunähern, ihnen Essen anzubieten und mit ihnen zu flirten.“ (Jones & Hoskins 1987) Das entsprechende Neuronale Netz besteht aus 6 Inputneuronen, wovon jedes Neuron für eine wahrgenommene Eigenschaft steht (große Ohren, große Augen, große Zähne, freundlich, faltig, schön). Die Verhaltensweisen von Rotkäppchen werden durch die 7 Neuronen der Outputschicht repräsentiert (weglaufen, schreien, Holzfäller suchen, auf Wange küssen, sich nähern, Essen anbieten, flirten). |
||||
|
||||
|
Jedes Neuron der Inputschicht (Wahrnehmung) wird mit sämtlichen Neuronen der Outputschicht (Verhalten) verbunden. Zunächst sind die Verbindungsstärken zufällig, und das Netzwerk produziert nur unsinniges Verhalten. Das Rotkäppchen-Netzwerk muss jetzt mit Hilfe überwachten Lernens (in diesem Fall der Delta-Lernregel) trainiert werden.
Dazu legt man ein Inputmuster der Trainingsmenge an und vergleicht das gewünschte Outputmuster mit dem tatsächlichen Output. Dann wird die Verbindungsstärke zwischen einem Input- und einem Outputneuron entweder erhöht oder erniedrigt, abhängig davon, ob das Inputneuron aktiv war und zum gewünschten Output beigetragen hat oder nicht. Dieses methodisch genau festgelegte Verfahren führt zu einer schrittweisen Annäherung an die gewünschten Outputmuster und nach mehreren Trainingsdurchgängen sind alle Verbindungsstärken richtig eingestellt, und das Rotkäppchen zeigt das gewünschte Verhalten. Mathematisch kann obiges Perceptron durch ein rechteckiges Zahlenschema mit 7 Zeilen und 6 Spalten dargestellt werden. Diese 7x6 Matrix bildet einen |
||||
|
||||
|
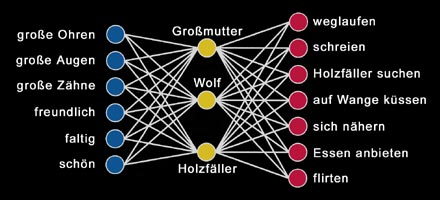
Man kann das Verhalten von Rotkäppchen aber auch durch ein dreischichtiges Netzwerk simulieren. Die Inputneuronen geben jetzt die wahrgenommenen Eigenschaften zunächst an die Neuronen des Hidden Layers (Zwischenschicht) weiter, und diese stellen durch Training ihre synaptischen Verbindungen so ein, dass der Input verallgemeinert und Inputcluster gebildet werden, die ihrerseits wieder outputrelevant sind. Anders gesagt: Durch die Einführung eines Hidden Layers wird das Netz abstraktionsfähig, denn die wahrgenommenen Eigenschaften werden jetzt in Kategorien zusammengefasst, und ein Neuron des Hidden Layers repräsentiert den Prototyp (in der Linguistik der typische Vertreter einer Kategorie) einer dieser Kategorien. Bei zu wenig Neuronen in der Zwischenschicht wird der Input zu allgemein geclustert und das Verhalten am Ausgang ist nicht mehr differenziert genug. Bei zu vielen Neuronen in der Zwischenschicht kann das Netz zwar seine Aufgabe erfüllen, aber es verliert seine Abstraktionsleistung. Im Fall des Rotkäppchen-Netzwerks ist die optimale Anzahl der Neuronen in der Zwischenschicht drei. Der Input wird jetzt in drei Kategorien eingeteilt, und die drei Neuronen der Zwischenschicht repräsentieren ihre Prototypen, denen wir jetzt die Namen Großmutter, Wolf und Holzfäller geben können.
Natürlich sind die Begriffe Großmutter, Wolf und Holzfäller schon als regelhafter Zusammenhang von wahrgenommenen Eigenschaften und zugehörigen Verhalten implizit in der Trainingsmenge vorhanden, aber als Systemeigenschaften treten sie erst im dreischichtigen Netzwerk zutage. Mathematisch gesprochen werden jetzt die Inputmuster zunächst durch eine 3x6 Matrix auf die Prototypen des Hidden Layers abgebildet, und deren Aktivitätsmuster wird anschließend mittels einer 7x3 Matrix als Verhaltensmuster ausgegeben. |
||||
|
Kanon |
||||
|
Abstraktionsleistung und Denken in Kategorien ist eine typisch menschliche Eigenschaft und wurde von Immanuel Kant (1724-1804) ausführlich in seiner Transzendentalphilosophie beschrieben. Beim Rotkäppchen-Netzwerk kann man zwar nicht von Denken sprechen, sondern nur von Reflexen auf eingehende Reize, trotzdem werden solche Modelle von künstlichen Neuronalen Netzen heute schon von der Psychologie benutzt, um menschliches Verhalten besser verstehen zu lernen. Die Frage, ob künstliche Neuronale Netze irgendwann einmal Bewusstsein besitzen werden, kann heute noch niemand beantworten. Begriffe wie Bewusstsein oder Subjekt haben sich bisher jedem Versuch eines naturwissenschaftlichen Zugangs erfolgreich entzogen. Das sollte nicht allzu sehr verwundern, war die neuzeitliche Wissenschaft doch von Anfang an bestrebt, das Subjekt aus ihrer Naturbeschreibung fernzuhalten.
Bei Kant ist es genau umgekehrt: Das Primäre ist das Subjekt. Menschliche Erkenntnis ist dort zwischen den Polen transzendentales Subjekt und Noumenon (Kants Ding an sich) aufgespannt. Das Subjekt kann das Noumenon nicht direkt sondern nur durch eine Art farbige Brille** erkennen. Das sind die apriorischen Anschauungsformen der Sinne und die Kategorien (Denkformen) des Verstandes. Erst durch diese konstitutiven Prinzipien des Subjekts nehmen wir eine geordnet erscheinende, objektive Außenwelt wahr. Damit das von diesem empirischen Subjekt (unser individuelles Ich) gesammelte Wissen systematisiert und zu einer Einheit geführt werden kann, besitzt das Subjekt auch noch regulative Prinzipien, das sind die transzendentalen Ideen der Vernunft. Dieser Kanon (allgemeiner Maßstab, festgesetzte Ordnung) der Vernunft ermöglicht, dass das empirische Subjekt in einem unendlichen Progress Richtung transzendentales Subjekt gezogen wird, sodass sich unser Erkennen immer mehr dem Ideal annähern kann, das in den transzendentalen Ideen vorgezeichnet ist. Mit anderen Worten: Dieser Kanon macht es möglich, dass im Laufe der Evolution die farbige Brille des Menschen immer transparenter bzw. der Spiegel immer klarer wird. Die Vernunft mit ihren transzendentalen Ideen ist sozusagen unser innerer Supervisor. Wenn sich nun ein künstliches Geschöpf wie das Rotkäppchen-Netzwerk selbstständig weiterentwickeln soll, dann benötigt es in seinem System ebenfalls etwas Ähnliches wie regulative Prinzipien. Ein solcher Kanon wäre aber in diesem Fall nur das Produkt des begrenzten menschlichen Verstandes. * Das menschliche Gehirn besitzt mehrere hundert Milliarden Neuronen und etwa eine Trillion (eine Eins mit 18 Nullen) synaptische Verbindungen. ** Sind transzendentales Subjekt und Noumenon identisch (wie im Deutschen Idealismus eines Fichte, Schelling oder Hegel), wird aus der farbigen Brille eine Art farbiger Spiegel. |
||||
|
© Copyright Peter Liendl und Gisela Klötzer |


home - back - top